
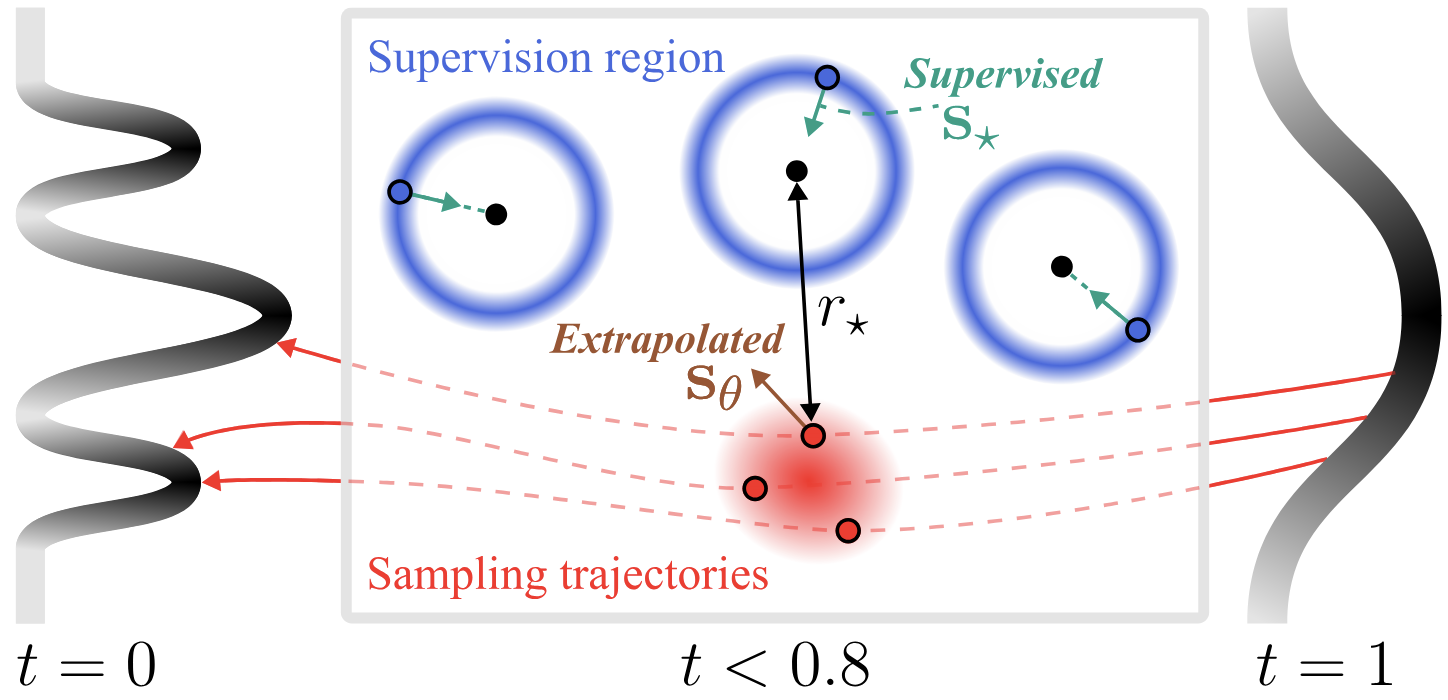

The flavor of the bitter lesson for computer vision
Computer vision conventionally maps images to intermediate representations (class, segmentation, 3D reconstruction, etc), but the "real" role of vision has always been as part of a perception-action loop. The LLM moment for vision won't mean SOTA on intermediate tasks, but instead intelligent, embodied agents. World models are the first glimpse. 3D in particular will become obsolete for training embodied intelligence models.


